Utiliser les données OSM pour connaître les cols et sommets franchis à partir d’un fichier GPX
Développement en Python d’un petit script capable de détecter les cols et sommets franchis à partir de trace GPS.

Loïc
Consultant Web

Chaque année, je passe des cols et gravit des sommets à pied (trail / randonnée) ou à vélo de route. J’enregistre chacune de mes sorties avec une montre Suunto ou mon téléphone et synchronise le tout sur Strava. Toutes mes activités sportives sont donc sur le web et en fin d’année, j’aimerai bien me faire un petit récap pour me remémorer où je suis passé sans me palucher toutes mes sorties. Après un peu de recherche et quelques lignes de codes, je peux désormais faire ça facilement. C’est parti pour les explications !
Récupérer les POIs où j’ai pu passer
Données OpenStreetMap
La première chose à faire, c’est de récupérer tous les POIs (Point Of Intereset ; dans mon cas les cols et sommet) où j’aurai pu passer, avec leurs coordonnées géographiques (latitude / longitude).
Pour avoir ce genre de données, il existe un super projet opensource qui est la base d’une bonne partie des projets cartographiques sur le Web : OpenStreetMap.

Le service Mapbox utilise les données OSM pour générer ses cartes
OpenStreetMap.org, propose d’exporter toutes les informations d’une zone affichée à l’écran. Malheureusement, cette zone est limitée en taille et impossible pour moi d’exporter tous les massifs où je me suis rendu, à moins de le faire en plusieurs fois. Je me suis donc tourné vers Geofabrik qui propose de télécharger toutes les données d’un pays ou d’une région.
A noter que les exports OpenStreetMap se font au format .OSM, qui sont des fichiers XML, qu’on peut lire facilement avec n’importe quel langage de programmation.
Geofabrik lui, propose les données au format .pbf, qui est un format compilé. Enfaite, ils ont été obligés de compiler les données car rien que l’Europe c’est presque 25Go donc imaginez en bon vieux XML…
J’ai donc récupéré le fichier Rhône-Alpes étant donné que 99.5% de mes sorties étaient dans cette zone.
Serveur MongoDB avec Docker
Pour stocker tous les POIs qui m’intéressent, j’ai fait le choix d’une base de données NoSQL MongoDB. À la base, j’avais fait ce choix car MongoDB propose des fonctionnalités géographiques sans installer quoi que ce soit en plus, mais finalement je n’en aurai pas eu besoin. Autre avantage, c’est que je ne perdrai pas de temps à imaginer une structure de données au préalable (MongoDB est « schemaless »).
Pour avoir un serveur MongoDB avec Docker :
docker run -p 27017:27017 -v /opt/mongodb/db:/data/db --name my-mongo -d mongo
Explication :
-p 27017:27017 pour mapper le port 27017 (port par défaut de mongoDB) du container avec le 27017 du host
-v /opt/mongodb/db:/data/db pour indiquer où stocker les données et ne pas les perdre au redémarrage de la machine / du container
--name my-mongo un jolie nom à notre container
-d pour détacher le container du terminal
mongo le nom de l'image utiliséComment se présente un fichier OSM ?
Avant de lire le fichier de données, il me semble intéressant d’expliquer rapidement ce qu’il contient pour mieux comprendre la suite des explications.
Comme je le disais plus haut, les fichiers OSM sont des fichiers au format XML. Ils contiennent :
- des nœuds (un point avec une latitude et une longitude)
- des chemins (ensemble de nœuds)
- des relations (ensemble de nœuds et chemin pour décrire une ligne de bus par exemple)
Ces éléments peuvent avoir des tags qui donnent des informations supplémentaires. Voilà comment se présente le nœud du Mont Ventoux :
<node id="411436529" visible="true" version="7" changeset="75561193" timestamp="2019-10-11T11:51:34Z" user="mirelon" uid="1270972" lat="44.1739649" lon="5.2783976">
<tag k="alt_name" v="Le Sommet"/>
<tag k="ele" v="1909"/>
<tag k="name" v="Mont Ventoux"/>
<tag k="natural" v="peak"/>
<tag k="prominence" v="1150"/>
<tag k="source" v="cadastre-dgi-fr source : Direction Générale des Impôts - Cadastre"/>
<tag k="tourism" v="attraction"/>
<tag k="website" v="http://www.veloventoux.com/?c=montVentoux"/>
<tag k="wikidata" v="Q209064"/>
<tag k="wikipedia" v="fr:Mont Ventoux"/>
</node>Les fichiers .PBF retrouvent les mêmes informations, ils ont juste été compilé et demande à être décompilé pour être lu.
Extraire les cols et sommets de la région Rhône-Alpes
J’ai choisi le langage Python et le package osmiter pour lire le fichier binaire .pbf et en extraire tous les cols et sommets pour les stocker dans la base de données. L’occasion pour moi de changer un peu de langage (et de galérer aussi !). Pardonnez-moi d’avance si ce code n’est pas des plus beaux 😄
J’ai donc écrit un programme qui lit chaque nœud du fichier rhone-alpes-latest.osm.pbf. Pour chaque nœud qui possède le tag natural avec pour valeur saddle (= col) ou peak (=sommet) et qui ont un nom (il y a des sommets ou cols sans nom parfois mais ça ne m’intéresse guère), je l’insère dans un tableau. Tous les 100 POIs, j’envoie le tableau en base de données. Sur environ 4500 points d’intérêts ça permet d’éviter 4500 appels à la base de données et de réduire ça à 450. Bon, c’était plus pour le fun car on fera ce processus une seul fois donc l’intérêt reste limité.
#!/usr/bin/python3
# coding: utf-8
from pymongo import MongoClient
import osmiter
client = MongoClient(host="localhost", port=27017)
db = client.osm
poi = db.poi
results = []
for feature in osmiter.iter_from_osm("rhone-alpes-latest.osm.pbf"):
if feature["type"] == "node" and "natural" in feature["tag"]:
if feature["tag"]["natural"] in ["saddle", "peak"] and "name" in feature["tag"]:
results.append({
'name': feature["tag"]["name"],
'type': feature["tag"]['natural'],
"coord": [feature["lat"], feature["lon"]],
})
if len(results) == 100:
db.poi.insert_many(results)
results = []
db.poi.insert_many(results)
print(str(db.poi.count()) + " POIs extracted !")Après quelques minutes de traitement, notre base de données se retrouve avec 4593 POIs. C’est beau l’Auvergne Rhône Alpes et bien rempli de cols & sommets !
Comparer les POIs avec mes traces GPS
Demander ses données Strava
Comme je le disais en introduction, toutes mes traces d’activités sportives sont sur Strava. Une aubaine car Strava propose de télécharger une archive contenant toutes ses informations.
Dans : Paramètres -> Mon compte -> Télécharger ou supprimer le compte -> Commencer -> Demander une archive.
Au bout de quelques minutes, je reçois par mail une archive avec toutes mes données. L’archive contient un dossier activities qui lui-même contient les fichiers de toutes mes activités. Etant donné que cela fait plusieurs années que j’utilise Strava, j’ai plusieurs années d’activités. Je me suis servi du fichier activities.csv pour faire le trie et garder uniquement les fichiers de l’année 2021.
J’avais des fichiers (pas tous, c’est assez curieux) compressé en gzip. Pour dézipper tous les fichiers gzippé :
gunzip *.gzJ’avais également des fichiers au format .fit. C’est (encore!) un fichier compilé. J’ai converti ça en .gpx (pour obtenir un fichier XML lisible sans passer par un package) à l’aide du soft gpsbabel.
sudo apt-get install gpsbabelfor file in *.fit; do
if [ -f "$file" ]; then
gpsbabel -i garmin_fit -f $file -o gpx -F $file.gpx
fi
doneComparer ses traces avec les POIs
Il ne me restait plus qu’à écrire un script qui lise mes fichiers GPX et regarde près de quel point je suis passé. J’ai choisi de continuer en Python, et voici le code final :
#!/usr/bin/python3
# coding: utf-8
from xml.dom import minidom
from pymongo import MongoClient
from haversine import haversine
import csv
import os
def extract(path, distanceAccepted):
# 1. Extract all point of .gpx file & date of first point
gpxPoints = []
xmldoc = minidom.parse(path)
date = xmldoc.getElementsByTagName('time')[1].firstChild.nodeValue
for point in xmldoc.getElementsByTagName('trkpt'):
gpxPoints.append({
'lat': float(point.attributes['lat'].value),
'lon': float(point.attributes['lon'].value),
})
# 2. Search max point
seq = [x['lat'] for x in gpxPoints]
maxlat = max(seq)
minlat = min(seq)
seq = [x['lon'] for x in gpxPoints]
minlon = min(seq)
maxlon = max(seq)
# 3. Get all POIs in this perimeters
client = MongoClient(host="localhost", port=27017)
db = client.osm
pois = db.poi.find(
{"coord.0": {"$gt": float(minlat), "$lt": float(maxlat)},
"coord.1": {"$gt": float(minlon), "$lt": float(maxlon)}}
)
# 4. Compare points with OSM point
for osmPoint in pois:
mostNear = []
osmObject = (osmPoint['coord'][0], osmPoint['coord'][1])
for point in gpxPoints:
mostNear.append(haversine(osmObject, (point["lat"], point["lon"]), unit='m'))
if mostNear and min(mostNear) < distanceAccepted:
with open('results_'+str(distanceAccepted)+'m.csv', 'a') as file:
writer = csv.writer(file)
writer.writerow([date, osmPoint["name"], str(round(min(mostNear), 0))])
for filename in os.listdir("activities"):
print("Treat " + filename)
extract("./activities/" + filename, 20)Quelques explications du script :
Pour chaque fichier présent dans le dossier activities, j’appelle la fonction extract avec en paramètre le path du fichier ainsi que la distance en mètre maximum entre un POIs et la trace pour qu’on considère que je suis passé par ce point.
La fonction extract() est assez simple mais voici quelques explications. Je récupère chaque point (une latitude et une longitude) du fichier dans un tableau gpxPoints. Je récupère ensuite la latitude et la longitude maximal et minimal. Je requête ensuite la base de données qui contient tous les POIs de la région Rhône Alpes pour récupèrer tous les POIs situé entre ces latitudes et longitudes maximales/minimales. Je finis par comparer chaque POIs aux coordonnées de ma trace. La fonction haversine() permet de calculer la distance entre 2 points à partir de coordonnées géographique. Si un des points de ma trace c’est trouvé à moins de X mètres du POIs, alors on ajoute la date, le nom du POIs et la plus petite distance entre lui et la trace dans un fichier CSV.
Note : j’ai utilisé minidom plutôt que xml.etree.ElementTree car j’ai longtemps galéré pour récupérer tous les élements trkpt du fichier .gpx jusqu’à renoncer et opter pour minidom.
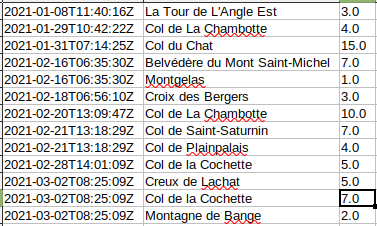
Resultat
Il ne reste plus qu’à ouvrir le fichier .csv, trié par date et voilà le résultat :
Limitations
Après avoir fait plusieurs essais, la distance maximum optimale pour déterminer qu’on est passé par un POIs me semble être de 20m. Cela peut paraître énorme mais c’est dû à deux facteurs :
- la précision de nos GPS
- la précision des POIs
L’addition de ces deux facteurs donne lieu à pas mal d’imprécision. Si l’on prend le « col de la Cochette » où je suis passé plusieurs fois par exemple, on se demande où peut bien être ce col.
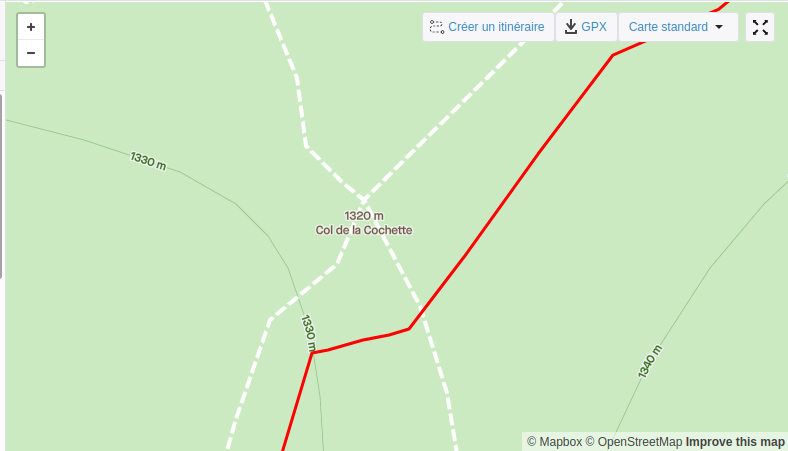
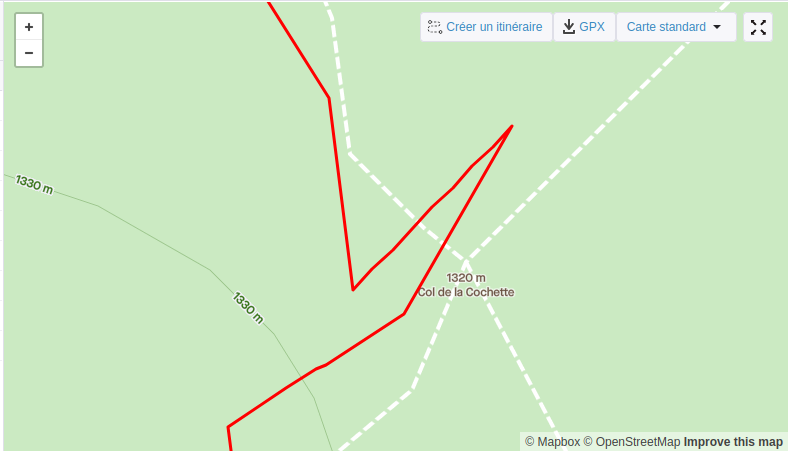
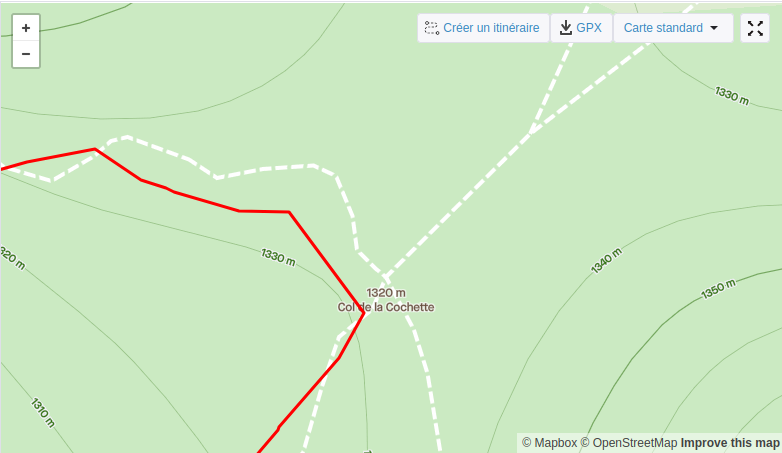
Lorsque l’on contribue au projet OSM pour placer des points ou tracer des chemins, on peut s’aider de photographies satellites. Malheureusement, ce col est en pleine forêt.. Dur dur de placer le point avec précision.

Il pourrait également être intéressant de rajouter lors de l’extraction des POIs les entrées de grottes (tag natural avec pour valeur cave_entrance), les glaciers (tag natural ; valeur glacier) les lacs (tag natural ; valeur water) ou encore les croix (tag man_made ; valeur cross).
Attention pour les lacs : j’habite près du Lac du Bourget et il m’arrive plusieurs fois dans la saison d’aller courir au bord de celui-ci. Autant dire qu’il risque de ressortir plusieurs fois dans le fichier. Mais c’est le seul moyen pour détecter quand on est passé aux abords d’un lac de montagne.
Pour finir, il y a certaines randonnées où l’intérêt réside dans le chemin (chemin de l’ancienne crémaillère du Revard par exemple) et aucun POIs n’est rencontré. Les balades sur ces chemins ne pourront malheureusement pas ressortir dans le fichier final.
Hormis ces petits aléas, je suis vraiment content de ce projet qui m’a permis de découvrir un peu OpenStreetMap et c’est vraiment le feu tant il y a de projets possibles autour des données cartographiques. J’ai également pu contribuer en ajoutant quelques chemins et c’est plutôt plaisant de les voir appaître dans les applications de tracé de parcours et de pouvoir s’en servir.